O Gemini 3.1 Flash TTS é o modelo de texto para voz com IA mais expressivo já lançado pelo Google — e está disponível gratuitamente para quem usa o Google AI Studio.
Mais do que converter texto em áudio, ele permite controlar como a voz fala: com emoção, ritmo, entonação e até sotaque regional.
Tudo isso por meio de comandos de texto simples, sem necessidade de gravação humana ou edição de áudio profissional.
- Prompts para imagens realistas com Nano Banana
- Gemini GEM: como criar seu assistente de IA gratuito
- Curso de Lovable completo – Veja como criar apps com IA
O que torna o Gemini 3.1 Flash TTS diferente dos modelos anteriores
A geração de voz com IA evoluiu muito nos últimos anos.
Porém, a maioria dos modelos ainda entrega um áudio genérico, sem personalidade e com entonação mecânica.
O Gemini 3.1 Flash TTS resolve esse problema com um recurso chamado audio tags — mais de 200 etiquetas de áudio inseridas diretamente no texto que instruem o modelo sobre como deve soar cada trecho da narração.
Na prática, você pode indicar que um personagem deve falar “sussurrando”, “com urgência”, “gritando” ou “com cautela”, e o modelo interpreta essas instruções e aplica na geração.
Além disso, é possível alternar entre diferentes locutores dentro do mesmo diálogo, cada um com seu próprio perfil de voz.
Esse nível de controle, até pouco tempo atrás, exigia um estúdio de gravação, um locutor profissional e horas de edição.
Agora, você obtém o mesmo resultado com um prompt bem estruturado.
Desempenho no benchmark: onde o Gemini 3.1 Flash TTS se posiciona
No ranking de TTS da Artificial Analysis — um benchmark que captura milhares de referências humanas para avaliar qualidade de síntese de voz — o Gemini 3.1 Flash TTS alcançou a pontuação de 1.211 pontos.
Esse resultado coloca o modelo em segundo lugar geral, atrás apenas do Winword TTS 1.5 Max.
Além disso, a Artificial Analysis posicionou o Gemini 3.1 Flash TTS no seu “quadrante mais atrativo”, pela combinação ideal entre alta qualidade de síntese e custo competitivo.
Para efeito de comparação, o modelo anterior da família Gemini ficava bem abaixo desse patamar.
O ganho em naturalidade e expressividade é perceptível tanto nos benchmarks quanto nos testes práticos com usuários reais.
Além disso, o modelo 3.1 Flash TTS suporta mais de 70 idiomas, incluindo o Português do Brasil, com capacidade de adaptar sotaque e ritmo conforme o contexto informado.
Segurança e identificação de conteúdo gerado por IA: o SynthID
Um aspecto importante do Gemini 3.1 Flash TTS que vai além da qualidade sonora é a proteção contra desinformação.
Todo áudio gerado pelo modelo é automaticamente marcado com a tecnologia SynthID, desenvolvida pelo Google DeepMind.
Trata-se de uma marca d’água imperceptível ao ouvido humano, integrada diretamente ao arquivo de áudio.
Ela permite identificar de forma confiável se um conteúdo foi gerado por IA, mesmo após edições e compressões comuns.
Portanto, ao usar o Gemini 3.1 Flash TTS em produções profissionais, o áudio gerado já carrega essa identificação de origem por padrão.
Como usar o Gemini 3.1 Flash TTS gratuitamente no Google AI Studio
O acesso ao Gemini 3.1 Flash TTS está disponível diretamente no Google AI Studio, sem custo para uso pessoal e testes.
Dentro da plataforma, acesse a opção Speech and Music no Playground.
Entre os modelos listados, você encontra o Gemini 3.1 Flash TTS Preview, identificado como novo e sem marcação de modelo pago.
A partir daí, você tem duas opções principais de uso:
- A primeira é aproveitar os templates prontos para se inspirar na criação de diálogos.
- A segunda é começar do zero clicando em Turn into natural speech, onde você descreve a cena, define o contexto e insere as falas de cada locutor com as tags desejadas.
Uma dica importante: ao finalizar a geração, faça o download imediato do arquivo de áudio.
O Playground não salva as sessões automaticamente.
Ao fechar o navegador ou a aba, todo o trabalho é perdido.
Como estruturar uma cena para obter o melhor resultado
O Gemini 3.1 Flash TTS performa melhor quando recebe contexto claro.
Ao criar uma narração, descreva o ambiente sonoro da cena — por exemplo, “uma floresta escura com água pingando ao fundo”.
Em seguida, defina o estilo: ritmo cadenciado, tom tenso, aceleração gradual para urgência.
Por fim, insira as falas com as audio tags correspondentes.
Outro ponto relevante é especificar o idioma desejado no campo de contexto.
Mesmo com vozes multilíngues, o modelo pode gerar áudio com sotaque estrangeiro se não receber essa instrução explicitamente.
Adicionar “idioma: português brasileiro” ao contexto resolve o problema e garante uma narração natural desde a primeira geração.
Para diálogos com múltiplos personagens, configure cada um individualmente nas Speaker Settings.
O modelo oferece diversas opções de voz, todas multilíngues e com características distintas de timbre e entonação.
Casos de uso práticos para IA para voz com o Gemini 3.1 Flash TTS
A combinação de controle granular, suporte multilíngue e acesso gratuito abre uma série de aplicações reais para o Gemini 3.1 Flash TTS.
Veja os principais:
Criadores de conteúdo podem gerar narrações para vídeos do YouTube, podcasts e reels sem depender de locução profissional. O modelo entrega áudio com naturalidade suficiente para uso em produção.
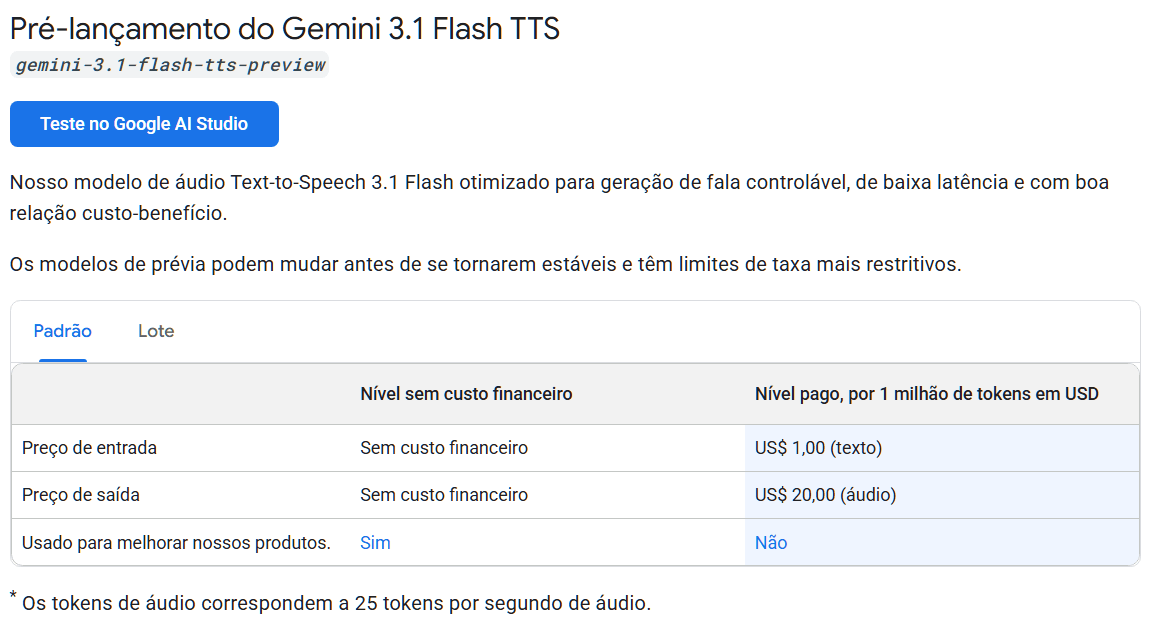
Desenvolvedores de aplicativos podem integrar o modelo via API para adicionar síntese de voz expressiva em produtos digitais. O custo oficial da API é de $1,00 por milhão de tokens de texto na entrada e $20,00 por milhão de tokens de áudio na saída — o dobro do modelo Gemini 2.5 Flash TTS anterior, que custava $0,50 e $10,00 respectivamente. Portanto, para projetos com alto volume de requisições, vale avaliar bem o custo antes de escalar.
Educadores e criadores de cursos podem produzir áudios didáticos com variação de ritmo e tom, tornando o conteúdo mais envolvente sem precisar regravar.
Profissionais de automação podem usar o modelo para criar respostas de voz em fluxos automatizados, integrando síntese de áudio diretamente em pipelines de produtividade.
Criar aplicativos com IA para voz usando o Gemini 3.1 Flash TTS
Além do uso direto no Playground, o Google AI Studio permite criar aplicativos completos com o Gemini 3.1 Flash TTS por meio da aba Build.
Você seleciona o modelo desejado, ativa a opção de conversão de texto em fala e descreve o aplicativo que quer criar.
Com um único prompt bem estruturado, é possível gerar um app funcional com seletor de idiomas, tags de características de voz — como alegre, brava, calma, confiante ou sussurrando —, controle de velocidade de reprodução e, no caso do Português do Brasil, variação de sotaque regional: carioca, mineiro, paulistano, caipira, nordestino e gaúcho.
Atenção ao ponto mais importante para quem pensa em publicar: apps criados dentro do Google AI Studio para uso pessoal não geram cobrança.
Porém, ao disponibilizar o aplicativo para outros usuários, é necessário configurar uma chave de API paga, pois o consumo passa a ser contabilizado por uso externo.
Texto para voz com IA: o que o Gemini 3.1 Flash TTS representa para o mercado
O lançamento do Gemini 3.1 Flash TTS consolida uma tendência clara no setor de síntese de voz com inteligência artificial: o controle criativo está migrando do estúdio para o prompt.
Ferramentas que antes exigiam equipamentos, técnicos e horas de pós-produção agora são acessíveis a qualquer pessoa com acesso a um navegador.
Somado a isso, o fato de o modelo estar disponível gratuitamente no Google AI Studio remove a barreira financeira para experimentação.
Desenvolvedores, criadores e profissionais de diversas áreas podem testar, iterar e validar ideias sem nenhum custo inicial.
O Gemini 3.1 Flash TTS está em fase de prévia para desenvolvedores, disponível via API do Google e pelo Google AI Studio.
Para empresas, também está acessível em pré-visualização no Vertex AI.
Para usuários do Google Workspace, o acesso chega via Google Vids.
Se você trabalha com produção de conteúdo, desenvolvimento de produtos digitais ou automação de processos que envolvem comunicação por voz, vale testar o modelo agora — enquanto o acesso ainda é gratuito e irrestrito para uso pessoal.