O Opus 4.7 chegou ao mercado em 16 de abril de 2026 como o modelo mais capaz da linha Opus da Anthropic — e também como o mais controverso.
Ele traz melhorias reais em tarefas longas, execução de agentes e consistência de raciocínio.
Porém, esconde uma pegadinha que está irritando desenvolvedores e usuários do plano Pro: na prática, ele custa significativamente mais do que o modelo anterior, mesmo com o preço oficial da API mantido igual.
O que é o Claude Opus 4.7 e o que ele promete
O Claude Opus 4.7 é uma atualização direta do Opus 4.6, não uma nova geração de modelos.
A Anthropic posiciona o lançamento com foco claro em três frentes: tarefas de longa duração, execução de agentes com menos supervisão e maior precisão no seguimento de instruções.
Uma das novidades mais relevantes é a capacidade de o modelo verificar o próprio output antes de retornar a resposta ao usuário.
Na prática, isso significa que o Claude Opus 4.7 revisa o que produziu antes de entregar o resultado final.
Esse comportamento reduz erros em projetos complexos e aumenta a confiabilidade em pipelines de agentes que rodam por longos períodos sem intervenção humana.
Além disso, o modelo traz suporte à funcionalidade Ultra Review, disponível no Claude Code por meio do comando /ultrareview.
Por meio dela, o modelo simula um revisor humano sênior, identificando falhas sutis de design e lacunas lógicas — indo além da simples verificação de erros de sintaxe.
A janela de contexto permanece em 1 milhão de tokens, o mesmo do Opus 4.6.
Para quem trabalha com codebases grandes, isso elimina a necessidade de resumir arquivos ou implementar RAG para navegar pelo projeto.
É possível enviar dezenas de arquivos completos e deixar o modelo encontrar o que precisa.
Outra novidade do lançamento é o nível de esforço xhigh, que oferece controle mais granular sobre a intensidade de raciocínio aplicada a cada tarefa.
Esse recurso se soma aos níveis já existentes — baixo, médio, alto e máximo — e permite calibrar com mais precisão o equilíbrio entre qualidade e consumo de tokens.
O recurso de orçamento de tarefas também chegou em versão beta.
Benchmarks: onde o Opus 4.7 se destaca — e onde fica para trás
Nos benchmarks divulgados pela Anthropic, o Opus 4.7 apresenta ganhos relevantes em relação ao seu antecessor em praticamente todas as categorias avaliadas.
- No SWE-bench Pro, o modelo atingiu 64,3%, contra 53,4% do Opus 4.6 e 57,7% do GPT-5.4.
- No SWE-bench Verified — subconjunto curado de 500 problemas reais do GitHub — o resultado foi de 87,6%, contra 80,8% do Opus 4.6 e 80,6% do Gemini 3.1 Pro.
- No CursorBench, que mede desempenho de codificação especificamente dentro do Cursor IDE, o Opus 4.7 atingiu 70%, contra 58% do Opus 4.6.
- No benchmark de tarefas de escritório GDPVal-AA, o Opus 4.7 alcançou 1.753 pontos em Elo.
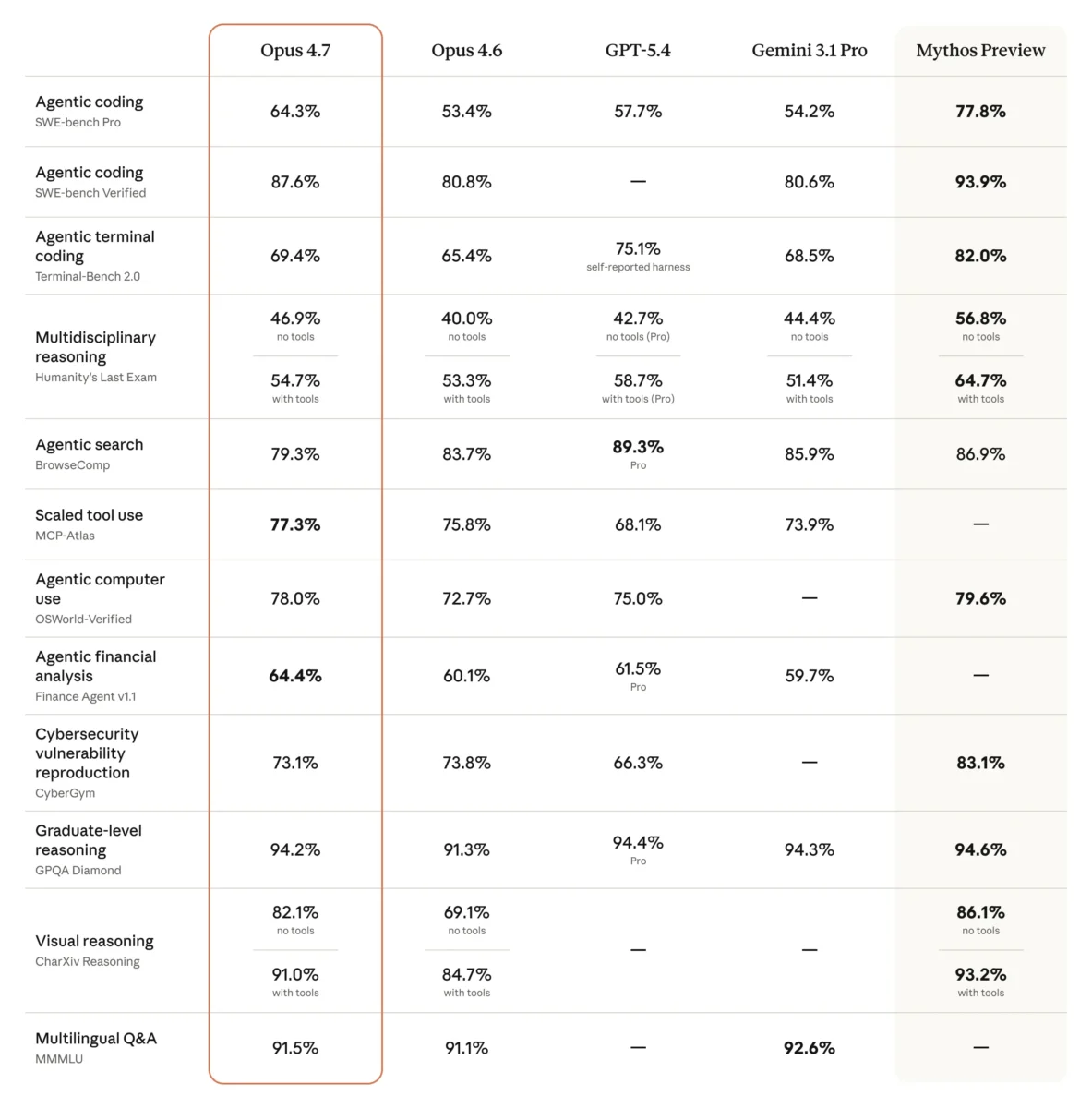
Para comparação, o GPT-5.4 registrou 1.674 e o Gemini 3.1 Pro ficou em 1.314 — bem atrás dos dois concorrentes diretos.
No raciocínio visual, o Opus 4.7 atingiu 91,0% no arXiv Reasoning com ferramentas, contra 84,7% do Opus 4.6.
Porém, há um ponto que a própria Anthropic reconhece abertamente: o Opus 4.7 fica significativamente atrás do Claude Mythos Preview, o modelo interno da empresa ainda não disponível ao público geral.
No SWE-bench Pro, o Mythos registrou 77,8% — bem acima dos 64,3% do Opus 4.7.
Em benchmarks de busca agêntica como o BrowseComp, o GPT-5.4 também supera o Opus 4.7, com 89,3% contra 79,3%.
A novidade em visão: resolução triplicada
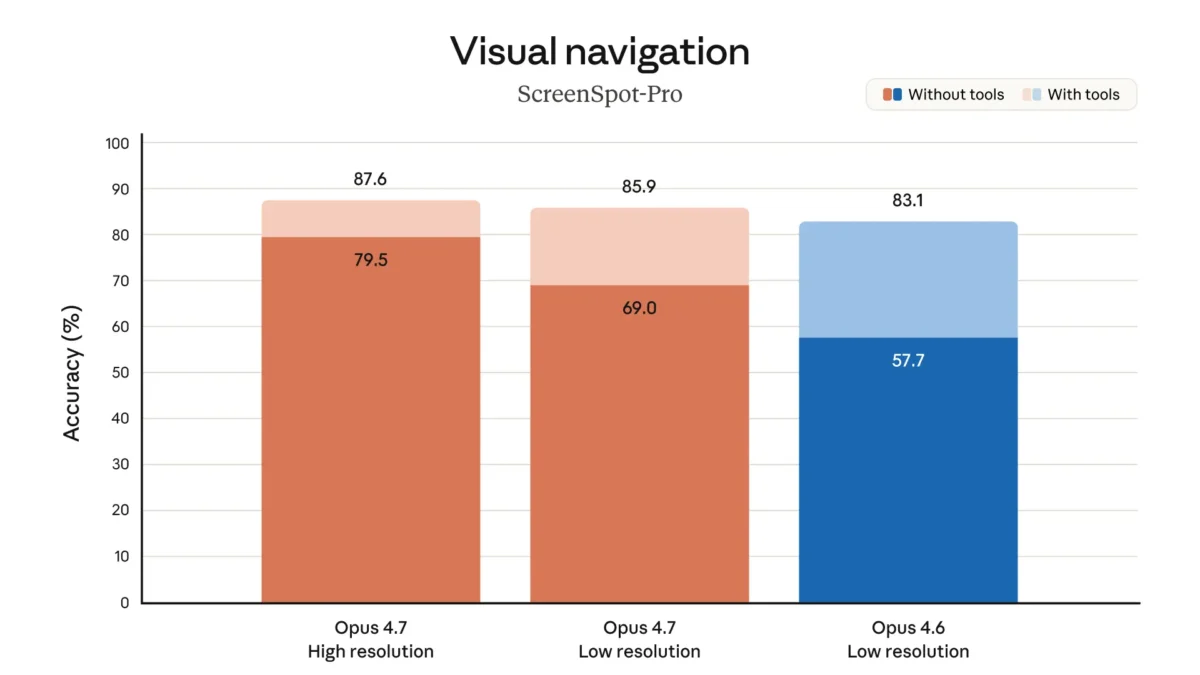
O Opus 4.7 traz uma melhoria concreta na capacidade multimodal que merece atenção.
O modelo passa a suportar imagens de até 2.576 pixels no lado longo — mais de três vezes o limite dos modelos Claude anteriores.
Isso equivale a aproximadamente 3,75 megapixels por imagem.
Na prática, capturas de tela de alta resolução, diagramas técnicos detalhados e documentos visuais complexos podem ser processados com muito mais precisão do que antes.
A confissão inédita da Anthropic: o modelo disponível é mais fraco do que o melhor desenvolvido
Um dos aspectos mais comentados do lançamento do Opus 4.7 não é técnico — é ético.
Pela primeira vez de forma oficial e pública, a Anthropic admitiu por escrito que o modelo disponibilizado ao mercado é menos capaz do que o melhor modelo que a empresa desenvolveu.
No blog oficial do lançamento, a empresa declarou que o Opus 4.7 apresenta um perfil de segurança semelhante ao Opus 4.6, com baixas taxas de comportamentos como engano, bajulação e conivência com uso indevido.
Em algumas medidas, como honestidade e resistência a ataques de injeção de prompt, o 4.7 representa uma melhoria.
Em outras, como a tendência a fornecer conselhos excessivamente detalhados sobre substâncias controladas, o modelo é ligeiramente inferior ao 4.6.
A empresa também confirmou que o Mythos Preview continua sendo o modelo mais bem alinhado que já treinou — e que ele segue restrito a um grupo seleto de cerca de 40 empresas participantes do projeto Glasswing.
Para o restante dos usuários, o Opus 4.7 é o teto disponível por enquanto.
Adicionalmente, o lançamento inclui uma salvaguarda automática que detecta e bloqueia solicitações de alto risco na área de cibersegurança.
Profissionais que atuam em áreas como testes de penetração e pesquisa de vulnerabilidades podem solicitar acesso por meio do novo Cyber Verification Program da Anthropic.
A pegadinha do preço: mesmo valor, mais tokens consumidos
O preço oficial da API do Opus 4.7 permanece em $5 por milhão de tokens na entrada e $25 por milhão de tokens na saída — exatamente igual ao Opus 4.6.
Porém, há dois fatores que tornam o modelo mais caro na prática.
O primeiro é o tokenizador atualizado.
A mesma entrada que era processada pelo Opus 4.6 pode ser mapeada para até 1,35 vezes mais tokens no Opus 4.7, dependendo do tipo de conteúdo.
Isso significa que, mesmo sem mudar nada no código ou nos prompts, você já vai gastar mais.
O segundo fator é o comportamento em níveis elevados de esforço.
O Opus 4.7 processa mais dados em turnos posteriores, especialmente em contextos com agentes.
Isso melhora a confiabilidade em tarefas complexas, mas aumenta o volume de tokens de saída gerados.
Na prática, testes realizados por usuários logo após o lançamento indicaram que o modelo é aproximadamente 33% a 50% mais caro do que o Opus 4.6 para as mesmas tarefas.
A própria Anthropic reconheceu a discrepância em comunicado oficial, explicando os dois fatores acima como causa do aumento no consumo.
Para quem usa a API via OpenRouter, o preço praticado é de $1,92 por milhão de tokens na entrada e $25 por milhão de tokens na saída.
O modelo também está disponível no Amazon Bedrock, no Vertex AI do Google Cloud e no Microsoft Foundry.
Pensamento adaptativo: recurso útil que pode sair caro
O Opus 4.7 traz o pensamento adaptativo como configuração padrão.
Nesse modo, o próprio modelo decide qual nível de raciocínio aplicar a cada tarefa, com base na complexidade percebida do prompt.
Essa decisão é feita automaticamente, sem intervenção do usuário.
O problema é que o modelo pode interpretar tarefas simples como complexas e acionar um nível de raciocínio elevado desnecessariamente.
Resultado: tokens esgotados mais rápido do que o esperado.
Na versão desktop do Claude, é possível controlar manualmente o nível de esforço, escolhendo entre baixo, médio, alto, extra alto (xhigh) e máximo.
Essa configuração dá ao usuário mais previsibilidade sobre o consumo.
Na versão via browser, a chave de pensamento adaptativo pode ser ativada ou desativada, mas sem o mesmo nível de granularidade.
Vários usuários relataram atingir o limite de taxa rapidamente após o lançamento — inclusive assinantes do plano Max, que custa $200 por mês.
Em alguns casos, uma única sessão com poucas iterações foi suficiente para esgotar os tokens disponíveis.
Como usar o Opus 4.7 sem desperdiçar tokens
Dado o alto consumo do modelo, a estratégia mais eficiente é usá-lo de forma cirúrgica.
Veja as principais recomendações práticas para quem quer extrair o melhor do Opus 4.7 sem comprometer o orçamento de tokens.
Comece com modelos mais leves. Use o Claude Sonnet 4.6 para construir a base do projeto.
Ele é significativamente mais econômico e capaz para a maioria das tarefas de desenvolvimento.
Só então leve o projeto para o Opus 4.7 para refinamento e revisão final.
Use o Ultra Review em contextos específicos. Essa funcionalidade é poderosa, mas consome bastante.
Reserve-a para pull requests grandes ou para bugs complexos que você não está conseguindo resolver com outros modelos.
Aproveite a janela de 1 milhão de tokens para refatorações. Em vez de resumir arquivos ou implementar buscas vetoriais, envie os arquivos completos e deixe o modelo navegar pelo contexto.
Para refatorações de módulos inteiros, essa abordagem tende a ser mais precisa e mais rápida.
Meça antes de escalar. Rode o modelo em um projeto de teste e compare o gasto com o Opus 4.6.
Se a qualidade subir proporcionalmente ao custo, a migração faz sentido.
Se não, use o Opus 4.7 apenas nas tarefas onde a diferença de desempenho é realmente percebida.
Monitore o consumo por sessão. No Claude Code, o comando /stats exibe o consumo detalhado de tokens por sessão.
Esse dado permite criar um acompanhamento de efetividade por token — uma métrica que grandes empresas já estão adotando internamente para avaliar o retorno de cada modelo.
Onde o Opus 4.7 já está disponível
O modelo está disponível diretamente na plataforma Claude para usuários com pelo menos o plano Pro.
Também está integrado ao Claude Code para desktop, ao Amazon Bedrock, ao Vertex AI e ao Microsoft Foundry.
No OpenRouter, o acesso exige uma chave de API paga.
Na LM Arena, o modelo está disponível apenas no modo batalha — não no modo direto.
O Opus 4.7 representa uma evolução real em relação ao 4.6, especialmente para quem trabalha com agentes de longa duração e tarefas que exigem raciocínio consistente ao longo de múltiplos turnos.
Porém, o aumento real no custo por tarefa é um fator que não pode ser ignorado antes de migrar definitivamente para o novo modelo.