O DeepSeek V4 foi lançado em 24 de abril de 2026 como a maior atualização já feita pelo laboratório chinês de IA.
Trata-se de uma família de dois modelos — V4-Pro e V4-Flash — completamente open-source, licenciados sob MIT.
Ambos chegam com janela de contexto de 1 milhão de tokens e preços que desafiam diretamente os modelos proprietários ocidentais.
O lançamento aconteceu no mesmo dia em que o GPT 5.5 estava dominando as discussões — e não foi por acaso.
- Gemini 3.1 Flash TTS: o modelo de voz do Google que controla emoção, ritmo e estilo em tempo real
- Claude Design: a ferramenta da Anthropic que cria sites, slides, apps e animações com IA
O que é o DeepSeek V4 e quais são suas variantes
O DeepSeek V4 é o quarto modelo da série flagship da DeepSeek, substituindo definitivamente o V3 e o V3.2.
Os dois modelos da família têm arquitetura Mixture-of-Experts (MoE), que ativa apenas uma fração dos parâmetros por token.
O DeepSeek V4-Pro tem 1,6 trilhão de parâmetros totais com 49 bilhões ativos por token, pré-treinado em 33 trilhões de tokens.
Isso o torna o maior modelo open-weights disponível atualmente — maior que o Kimi K2.6 (1,1T) e mais que o dobro do DeepSeek V3.2 (671B).
O DeepSeek V4-Flash tem 284 bilhões de parâmetros totais com 13 bilhões ativos por token, treinado em 32 trilhões de tokens.
Ambos suportam janela de contexto de 1 milhão de tokens com saída máxima de 384.000 tokens — três vezes mais que o Claude Opus 4.7 e o GPT 5.4, que limitam a saída a 128.000 tokens.
Os pesos de ambos os modelos estão disponíveis gratuitamente no Hugging Face, e a API foi disponibilizada no dia do lançamento.
Três modos de raciocínio
O DeepSeek V4 oferece três modos de operação: Non-Thinking para respostas rápidas, Thinking para raciocínio padrão e Think Max para esforço máximo em tarefas complexas.
No modo Think Max, o modelo recebe orçamento expandido de tokens de raciocínio, o que melhora resultados em matemática avançada e tarefas agênticas difíceis.
Para o modo Think Max, a DeepSeek recomenda configurar a janela de contexto com no mínimo 384.000 tokens.
Arquitetura: o que mudou em relação ao V3.2
A inovação arquitetural mais relevante do DeepSeek V4 é o mecanismo de atenção híbrida.
O modelo combina Compressed Sparse Attention (CSA) e Heavily Compressed Attention (HCA) para lidar com contextos longos com muito menos custo computacional.
Em contextos de 1 milhão de tokens, o V4-Pro usa apenas 27% dos FLOPs de inferência de token único e 10% da memória KV cache em comparação ao V3.2.
O V4-Flash vai ainda mais longe: usa apenas 10% dos FLOPs e 7% do KV cache em relação ao V3.2 no mesmo contexto de 1M tokens.
Além disso, o modelo incorpora Manifold-Constrained Hyper-Connections (mHC) para melhorar a estabilidade na propagação de sinais entre camadas.
Outra inovação é o uso do otimizador Muon durante o treinamento, que acelera a convergência.
Todas essas mudanças tornam o DeepSeek V4 estruturalmente mais eficiente — não apenas maior.
Preço: a vantagem mais clara do DeepSeek V4
A diferença de preço entre o DeepSeek V4 e os modelos proprietários é expressiva.
O V4-Flash custa $0,14 por milhão de tokens na entrada e $0,28 por milhão na saída — tornando-o mais barato que o GPT-5.4 Nano, Gemini 3.1 Flash e Claude Haiku 4.5.
O V4-Pro custa $1,74 por milhão de tokens na entrada e $3,48 por milhão na saída — aproximadamente 7 vezes mais barato que o GPT 5.5 e o Claude Opus 4.7.
Cache hits são cobrados a apenas 20% da taxa de entrada padrão, o que gera economia significativa em aplicações com prompts repetitivos.
Para equipes que processam grandes volumes de texto, a diferença é ainda mais expressiva na prática.
A IA chinesa mantém sua tradição de agressividade nos preços — e o V4 faz isso sem comprometer a capacidade de competir com modelos de ponta.
Benchmarks: onde o DeepSeek V4 se posiciona
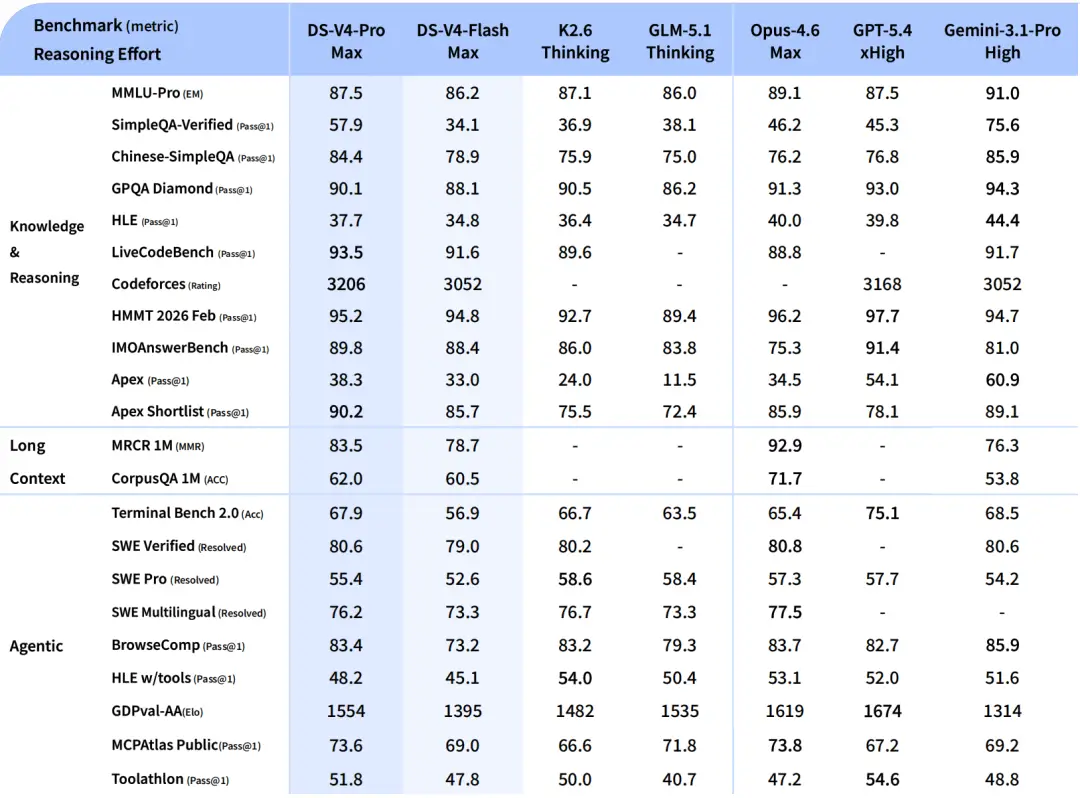
Os benchmarks do DeepSeek V4 mostram um modelo que chega muito próximo dos líderes ocidentais — especialmente considerando seu preço.
Terminal-Bench 2.0
No Terminal-Bench 2.0 — benchmark de fluxos de trabalho em linha de comando que envolve planejamento, iteração e coordenação de ferramentas — o V4-Pro marcou 67,9% e o V4-Flash marcou 56,9%.
Para comparação, o GPT 5.5 lidera com 82,7% e o Claude Opus 4.7 registrou 69,4%.
O V4-Pro fica apenas 1,5 ponto percentual abaixo do Opus 4.7 nesse benchmark agêntico — por uma fração do preço.
SWE-bench Verified
No SWE-bench Verified, o resultado é ainda mais próximo da concorrência.
O DeepSeek V4-Pro atingiu 80,6% e o V4-Flash marcou 79,0% — contra 80,8% do Claude Opus 4.6.
A diferença entre o V4-Pro e o Opus 4.6 é de apenas 0,2 ponto percentual nesse benchmark de desenvolvimento de software.
Vale destacar que o Claude Opus 4.7, versão mais recente da Anthropic, marcou 87,6% no SWE-bench Verified — abrindo uma margem maior sobre o V4-Pro nessa categoria.
SWE-bench Pro
No SWE-bench Pro — versão mais difícil do benchmark de resolução de issues reais do GitHub — o V4-Pro registrou 55,4% e o V4-Flash 52,6%.
O Claude Opus 4.7 lidera nessa categoria com 64,3%, e o GPT 5.5 marcou 58,6%.
LiveCodeBench e competição de programação
No LiveCodeBench Pass@1, o V4-Pro atingiu 93,5% e o V4-Flash 91,6% — ambos bem acima do Gemini 3.1 Flash e do GPT-5.4 Mini.
No Codeforces, o V4-Pro alcança rating 3.206, posicionando-se entre os 23 melhores competidores humanos da plataforma.
Orquestração de ferramentas: MCPAtlas e Toolathlon
No MCPAtlas Public — benchmark de orquestração de ferramentas do Scale AI —, o V4-Pro marcou 73,6%, ficando a apenas 0,2 ponto do Claude Opus 4.6-Max (73,8%).
No Toolathlon, o V4-Pro registrou 51,8%, superando o Kimi K2.6 (50,0%), o GLM-5.1 (40,7%) e o Gemini 3.1 Pro (48,8%).
Esses resultados mostram que o V4-Pro é competitivo em tarefas agênticas com uso de ferramentas — não apenas em codificação isolada.
Matemática e conhecimento geral
- No modo V4-Pro-Max, o modelo atinge 95,2% no HMMT 2026 February — contra 96,2% do Claude Opus 4.6 e 97,7% do GPT-5.4 nesse mesmo benchmark.
- No HLE (Humanity’s Last Exam), o V4-Pro marca 37,7%, ficando abaixo do Claude Opus 4.6 (40,0%), do GPT-5.4 (39,8%) e do Gemini 3.1 Pro (44,4%).
- No SimpleQA-Verified, o V4-Pro registra 57,9% contra 75,6% do Gemini — revelando uma lacuna relevante em recuperação de conhecimento factual.
A DeepSeek estima que essa defasagem equivale a 3 a 6 meses em relação aos modelos de ponta ocidentais no momento.
Velocidade e throughput para uso em desenvolvimento
Para quem usa LLMs em desenvolvimento de software, a velocidade de resposta importa tanto quanto a qualidade.
- O V4-Flash entrega 82,7 tokens por segundo com tempo até o primeiro token de 1,04 segundos — velocidade bem acima da mediana de modelos open-weight de tamanho similar (56,5 t/s).
- O V4-Pro opera a aproximadamente 36,8 tokens por segundo com latência de 1,28 segundos — ritmo comparável ao Claude Opus 4.7, que varia entre 35 e 43 tokens por segundo.
Portanto, o DeepSeek V4 Pro chega ao mercado com velocidade competitiva logo no lançamento — algo que outros modelos open-source grandes, como Kimi K2.6 e GLM, geralmente não conseguem oferecer de imediato.
Integração e compatibilidade com ferramentas de desenvolvimento
O DeepSeek V4 foi integrado nativamente com ferramentas de desenvolvimento agêntico como Claude Code, OpenClaw e OpenCode.
A API suporta os formatos OpenAI ChatCompletions e Anthropic API — o que significa que a integração não exige mudança de base URL, apenas atualização do parâmetro do modelo.
Para quem usa OpenRouter, o acesso ao V4-Pro e ao V4-Flash já está disponível, permitindo conectar o modelo a harnesses como Claude Code, VS Code e Cursor.
Uma atenção importante para desenvolvedores: os modelos deepseek-chat e deepseek-reasoner serão descontinuados após 24 de julho de 2026. Migrações devem ser feitas para os IDs explícitos deepseek-v4-pro ou deepseek-v4-flash antes dessa data.
Limitações importantes do DeepSeek V4
O DeepSeek V4 suporta apenas texto como entrada e saída.
Diferente do GPT 5.5 e do Gemini 3.1 Pro, ele não processa áudio, vídeo ou imagens.
Isso limita seu uso em fluxos de trabalho multimodais — como análise de screenshots de interfaces, geração de imagens ou interpretação de diagramas visuais.
Além disso, o V4-Pro no modo de raciocínio máximo é bastante verboso, gerando muito mais tokens por resposta do que a média dos modelos concorrentes.
Para auto-hospedagem, o V4-Flash é o alvo prático: com 284B parâmetros e 13B ativos por token, cabe em configurações multi-GPU acessíveis para equipes de médio porte.
O V4-Pro, com 1,6 trilhão de parâmetros totais, exige infraestrutura de cluster significativa — a maioria das equipes usará a API da DeepSeek para o Pro.
DeepSeek V4 vale a pena para desenvolvimento de software real?
A resposta depende do tipo de tarefa e do orçamento disponível.
Em benchmarks de desenvolvimento de software como SWE-bench Verified e LiveCodeBench, o V4-Pro chega muito próximo do Claude Opus 4.6 por uma fração do preço.
Em orquestração de ferramentas via MCPAtlas e Toolathlon, o DeepSeek V4 Pro supera o Gemini 3.1 Pro e se aproxima do Opus 4.6.
Já em tarefas agênticas mais complexas no Terminal-Bench e em conhecimento factual, o GPT 5.5 e o Claude Opus 4.7 ainda lideram com margem.
Porém, a relação desempenho por dólar do DeepSeek V4 é difícil de ignorar para equipes que trabalham com alto volume de requisições ou querem reduzir custos sem abrir mão de qualidade próxima ao estado da arte.
Para projetos que começam do zero, o V4-Pro via API já demonstra capacidade de criar aplicações funcionais complexas em uma única sessão — aproveitando a janela de saída de 384K tokens, três vezes maior que os concorrentes proprietários.
O modelo open-source mais capaz disponível hoje chega com um argumento claro: inteligência de nível próximo ao frontier, com código aberto e preço acessível.