O GPT 5.5 foi lançado oficialmente pela OpenAI em 23 de abril de 2026 como o modelo mais inteligente e intuitivo da empresa até o momento.
Trata-se do primeiro modelo completamente retreinado desde o GPT-4.5 — não é uma atualização incremental.
A arquitetura é nativamente omnimodal, processando texto, imagens, áudio e vídeo em um único sistema unificado.
O codename interno do modelo era Spud, que circulou em arquivos internos antes do anúncio oficial.
O que é o GPT 5.5 e por que ele é diferente dos modelos anteriores
O novo modelo da OpenAI foi projetado para executar tarefas complexas de forma autônoma, com menos intervenção humana.
Ele escreve e depura código, pesquisa online, analisa dados, cria documentos e planilhas, opera softwares e transita entre ferramentas até concluir uma tarefa.
A diferença central em relação ao GPT 5.4 é a capacidade de entender o objetivo do usuário mais rapidamente.
O modelo planeja, usa ferramentas, verifica o próprio trabalho, lida com ambiguidade e continua executando sem que você precise gerenciar cada etapa.
Além disso, o GPT 5.5 é mais eficiente em tokens do que o modelo anterior.
Ele usa menos tokens para chegar ao mesmo resultado, o que tende a compensar parcialmente o aumento no preço por token.
Para quem o GPT 5.5 está disponível
O GPT 5.5 está disponível para usuários dos planos Plus, Pro, Business e Enterprise no ChatGPT e no Codex.
O GPT 5.5 Pro — versão com raciocínio paralelo estendido em questões mais difíceis — está disponível apenas para assinantes Pro, Business e Enterprise.
A versão Go também tem acesso ao GPT 5.5 dentro do Codex, representando uma opção mais acessível para desenvolvedores.
A API do GPT 5.5 e do GPT 5.5 Pro foi disponibilizada em 24 de abril de 2026, um dia após o lançamento público, com salvaguardas de segurança adicionais aplicadas.
Preço da API do GPT 5.5: quanto custa usar o modelo
O GPT 5.5 base custa $5 por milhão de tokens na entrada e $30 por milhão de tokens na saída na API.
Esses valores representam o dobro do preço do GPT 5.4, que custava $2,50 e $15 respectivamente.
O GPT 5.5 Pro tem precificação significativamente mais alta: $30 por milhão de tokens na entrada e $180 por milhão de tokens na saída.
A janela de contexto do modelo é de 922.000 tokens, adequada para repositórios de código e documentos longos.
Na prática, o custo total por tarefa tende a ser menor do que o do GPT 5.4, pois o modelo consome menos tokens para completar o mesmo trabalho.
GPT 5.5 vs. Claude Opus 4.7: comparação nos benchmarks
A comparação entre GPT 5.5 e Claude Opus 4.7 não tem um vencedor absoluto.
Cada modelo lidera em categorias distintas, e a escolha depende do tipo de tarefa.
Onde o GPT 5.5 supera o Claude Opus 4.7
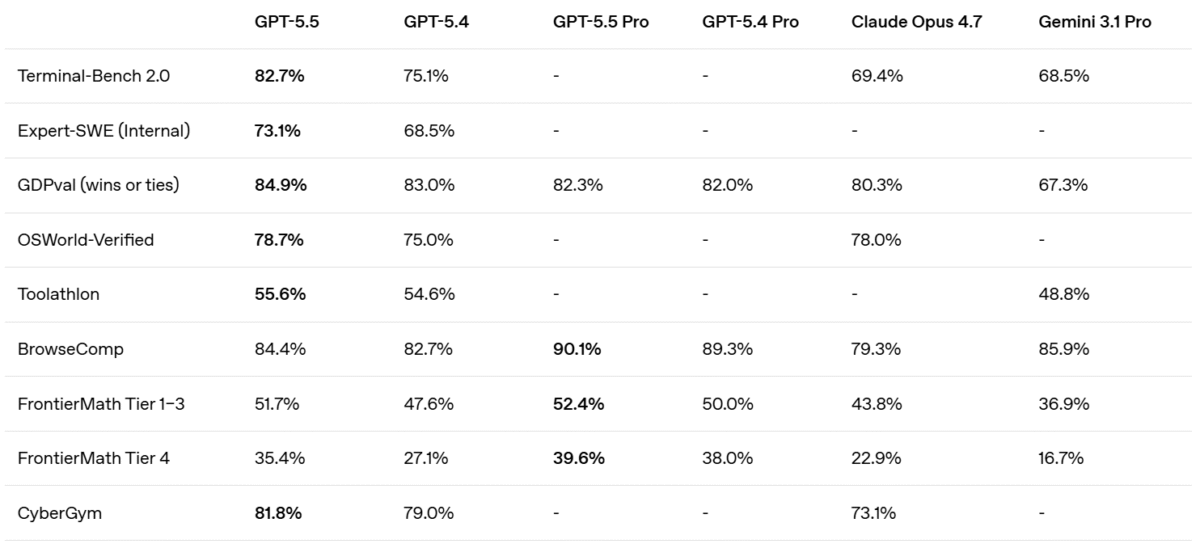
- Terminal-Bench 2.0: o GPT 5.5 atingiu 82,7%, contra 69,4% do Claude Opus 4.7 e 68,5% do Gemini 3.1 Pro.
- GDPval (benchmark de tarefas profissionais em 44 ocupações): GPT 5.5 registrou 84,9%, contra 80,3% do Claude Opus 4.7 e 67,3% do Gemini 3.1 Pro.
- CyberGym: GPT 5.5 marcou 81,8%, contra 73,1% do Claude Opus 4.7.
- OSWorld-Verified: GPT 5.5 atingiu 78,7%, superando por estreita margem os 78,0% do Claude Opus 4.7.
- FrontierMath Tier 4: GPT 5.5 registrou 35,4%, contra 22,9% do Claude Opus 4.7 e 16,7% do Gemini 3.1 Pro.
Onde o Claude Opus 4.7 supera o GPT 5.5
- SWE-bench Pro: o Claude Opus 4.7 lidera com 64,3%, contra 58,6% do GPT 5.5.
- SWE-bench Verified: Claude Opus 4.7 atingiu 87,6% — o GPT 5.5 não divulgou resultado nesse benchmark.
- HLE sem ferramentas: o Claude Opus 4.7 marcou 46,9%, contra 41,4% do GPT 5.5.
- MCP-Atlas (benchmark de orquestração de ferramentas): Claude Opus 4.7 lidera com 79,1%, contra 75,3% do GPT 5.5 e 78,2% do Gemini 3.1 Pro.
Onde o Gemini 3.1 Pro supera o GPT 5.5 base
No BrowseComp, o Gemini 3.1 Pro marcou 85,9%, contra 84,4% do GPT 5.5 base.
Porém, o GPT 5.5 Pro supera ambos no BrowseComp, com 90,1%.
Expert-SWE: o benchmark interno da OpenAI
O Expert-SWE é um benchmark interno da OpenAI para tarefas de codificação com tempo médio de conclusão humana de 20 horas.
Nesse benchmark, o GPT 5.5 atingiu 73,1%, contra 68,5% do GPT 5.4.
Como se trata de um benchmark interno, o Claude Opus 4.7 não foi avaliado nessa métrica, o que limita a comparação direta.
O que o GPT 5.5 faz na prática: codificação, automação e Browser Use
Codificação agêntica no Codex
O GPT 5.5 cria aplicações completas a partir de um único prompt, sem necessidade de iterações adicionais.
Desenvolvedores testaram criação de sites com animações, réplicas de sistemas operacionais, jogos 3D e simulações científicas — tudo com um único comando.
O modelo também ajudou a reescrever a própria infraestrutura de servidores da OpenAI antes do lançamento, resultando em ganho de eficiência no processamento.
Browser Use: testes automáticos de interface
O Browser Use é uma funcionalidade disponível diretamente no Codex.
Com ela, você instrui o modelo a navegar em um site e testar automaticamente se os elementos da interface estão funcionando.
O modelo move o cursor, clica em botões, navega entre páginas e verifica o comportamento da aplicação sem intervenção manual.
Essa funcionalidade é especialmente útil para equipes de desenvolvimento que precisam validar interfaces antes de publicar atualizações.
Níveis de raciocínio disponíveis
O GPT 5.5 oferece dois modos de raciocínio.
O modo padrão equilibra velocidade e profundidade de análise para a maioria das tarefas.
O modo estendido processa questões mais complexas por mais tempo, consumindo mais tokens em troca de maior precisão.
Cibersegurança: Trusted Access for Cyber e classificação de risco
O GPT 5.5 foi classificado como “High” no Preparedness Framework da OpenAI para capacidades biológicas, químicas e de cibersegurança.
Essa é a mesma classificação dos modelos anteriores — não chegou ao nível “Critical”.
O programa Trusted Access for Cyber oferece acesso expandido a capacidades avançadas de cibersegurança para pesquisadores verificados.
Profissionais responsáveis pela defesa de infraestrutura crítica podem solicitar acesso com menos restrições para trabalho legítimo de segurança.
Pesquisa científica e biologia: onde os dois modelos estão investindo
O GPT 5.5 apresenta ganhos em fluxos de trabalho de pesquisa científica e técnica, especialmente em análise de dados em múltiplas etapas.
O GeneBench — novo benchmark focado em análise de dados científicos em genética e biologia quantitativa — foi usado como referência no lançamento.
Tanto a OpenAI quanto a Anthropic têm investido fortemente em capacidades voltadas à biologia molecular.
O Claude Opus 4.7 registrou salto de 46,9% para 74% em benchmarks de biologia entre versões.
Ambas as empresas parecem posicionar seus modelos para aplicações em pesquisa médica e descoberta de tratamentos.
GPT 5.5 ou Claude Opus 4.7: qual escolher
A escolha entre os dois modelos depende do tipo de tarefa e do ambiente de execução.
Para codificação agêntica em terminal, automação de testes e tarefas que exigem planejamento de múltiplas etapas, o GPT 5.5 no Codex apresenta vantagem clara.
Para resolução de problemas reais do GitHub, orquestração de ferramentas e raciocínio sem ferramentas, o Claude Opus 4.7 ainda lidera.
Em termos de custo, o GPT 5.5 é mais caro por token, mas mais eficiente — usando menos tokens por tarefa.
O Claude Opus 4.7, por sua vez, tem preço por token menor, mas consome até 33% a 50% mais tokens do que o modelo anterior da Anthropic.
Um ponto importante é que o desempenho de qualquer modelo depende não apenas do modelo em si, mas do AI Harness — o sistema de cache, retentativas e orquestração de subagentes de cada plataforma.
O mesmo modelo pode ter desempenho diferente dentro do Codex, do Claude Code ou do Cursor, dependendo de como cada plataforma implementa esse sistema.
A recomendação prática é testar ambos os modelos nas tarefas específicas do seu contexto antes de migrar definitivamente.